一、http状态码
1、引例阐述
在讲状态吗之前,我们先来了解什么是状态码。比如百度网站:
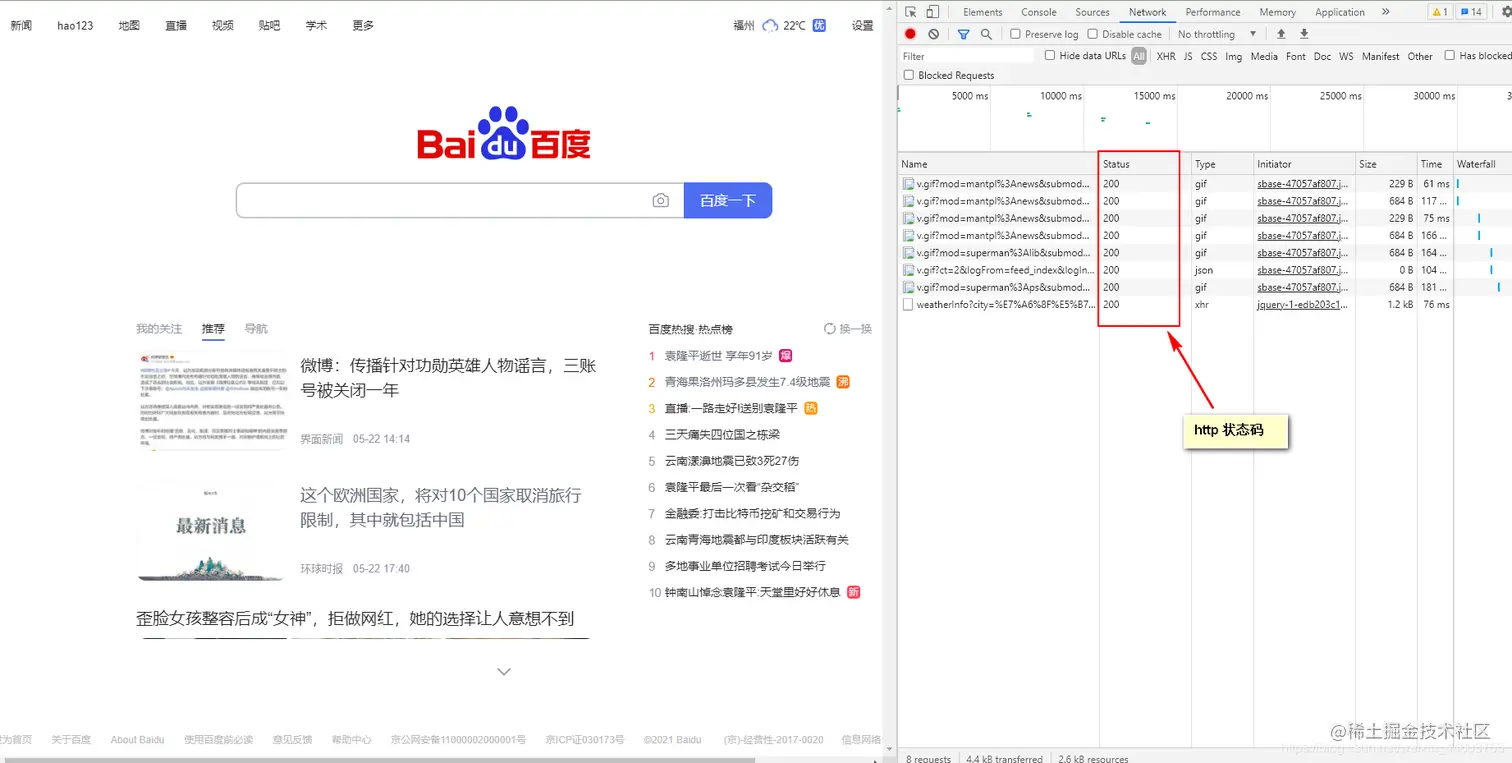
大家可以看到,上图中圈红圈的部分就是 http 的状态码,常见的状态码有200,400,404等等。接下来对状态码的一些基础知识进行介绍。
2、状态码分类
下表给出状态码分类。
| 状态码 | 含义 | 解释说明 |
|---|
| 1xx | 服务器收到请求 | 收到1xx开头的请求表示服务端已经收到请求,但是还没有返回信息给客户端 |
| 2xx | 请求成功,如200 | 表示客户端已经成功请求数据 |
| 3xx | 重定向,如302 | 客户端收到3xx开头的状态码时,表示此时服务端已经不再管客户端所请求地址,让客户端去请求另外的地址 |
| 4xx | 客户端错误,404 | 表示当客户端请求了一个服务端完全不认识的地址时,就会报出4xx的错误 |
| 5xx | 服务端错误,如500 | 表示此错误来源于服务端,比如服务端写的接口出现了bug等问题 |
3、常见状态码
常见的有200(正常) 、404(无法找到该网页资源) 、304(跳转页面) 、500(服务器错误)等,具体如下:
| 状态码 | 含义 | 用途 |
|---|
| 200 | OK 成功 | 一般用于 GET 和 POST 请求 |
| 301 | Redirect Permanently 永久重定向 | 配合location,浏览器自动处理 |
| 302 | Found 临时重定向 | 配合location,浏览器自动处理 |
| 304 | Not Modified 资源未被修改 | 所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 404 | Not Found 资源未找到 | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站 设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 403 | Forbidden 没有权限 | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 500 | Internal server Error 服务器错误 | 服务器内部错误 |
| 504 | Gateway Time-out网关超时 | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
下面详细阐述 301 和 302 。
301 永久重定向:
常见场景有,比如说你的一个网站,域名到期了,或者域名你不想用了,那么老的域名就可以返回一个 301 状态码并配合 location 让 location 的值等于新的域名,最终进行跳转,之后浏览器会记住新的域名,不会再访问老的域名。
302 临时重定向:
常见场景有百度,知乎、简书等等。比如说我们要在百度进入菜鸟教程,搜索出来后有一系列的列表,我们可以选择一个去进行一个点击。点击的那个不会直接进入菜鸟教程,而是先跳转到百度设置的一个临时地址,之后再跳转到菜鸟教程真实的地址。
4、关于协议和规范
二、http 方法
1、传统的methods
get 获取服务器的数据;
post 向服务器提交数据;
head 用户获取报头。
2、现在的methods
3、Restful API
(1)Restful API是什么?
Restful API 是一种新的 API 设计方法(早已推广使用)。
传统 API 设计:把每个 url 当做一个功能。
Restful API 设计:把每个 url 当做一个唯一的资源。
(2)如何设计成一个资源?
1)尽量不用url参数
2)用method表示操作类型
传统 API 设计:
post请求:/api/create-article
post请求:/api/update-article?id=100
get请求:/api/get-article?id=100
Restful API 设计:
post请求:/api/article
post请求:/api/article/100
get请求:/api/article/100
三、http 头部(http headers)
1、常见的Request headers
| 请求头 | 含义 |
|---|
| Accept | 浏览器可接收的数据格式 |
| Accept-Encoding | 浏览器可以接收的算法,如gzip |
| Accept-Language | 浏览器可接收的语言,如zh-CN |
| Connection | keep-alive 一次TCP连接重复使用 |
| cookie | 客户端接收到的Cookie信息 |
| Host | 指定原始的 URL 中的主机和端口 |
| User-Agent(简称UA) | 浏览器内核信息 |
| Content-type | 发送数据的格式,如application/json |
2、常见的Response headers
| 响应头 | 含义 |
|---|
| Content-type | 返回数据的格式,如application/json |
| Content-length | 返回数据的大小,多少字节 |
| Content-Encoding | 返回数据的压缩算法,如gzip |
| Set-Cookie | 服务端向客户端设置cookie |
四、http 缓存
1、关于缓存的介绍
(1)什么是缓存
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。
(2)为什么需要缓存?
如果没有缓存的话,每一次网络请求都要加载大量的图片和资源,这会使页面的加载变慢许多。那缓存的目的其实就是为了尽量减少网络请求的体积和数量,让页面加载的更快。
(3)哪些资源可以被缓存?——静态资源(js、css、img)
2、http 缓存策略(强制缓存 + 协商缓存)
(1)强制缓存
1)强制缓存是什么?
强制缓存就是文件直接从本地缓存中获取,不需要发送请求。
2)图例
先看第一个图。
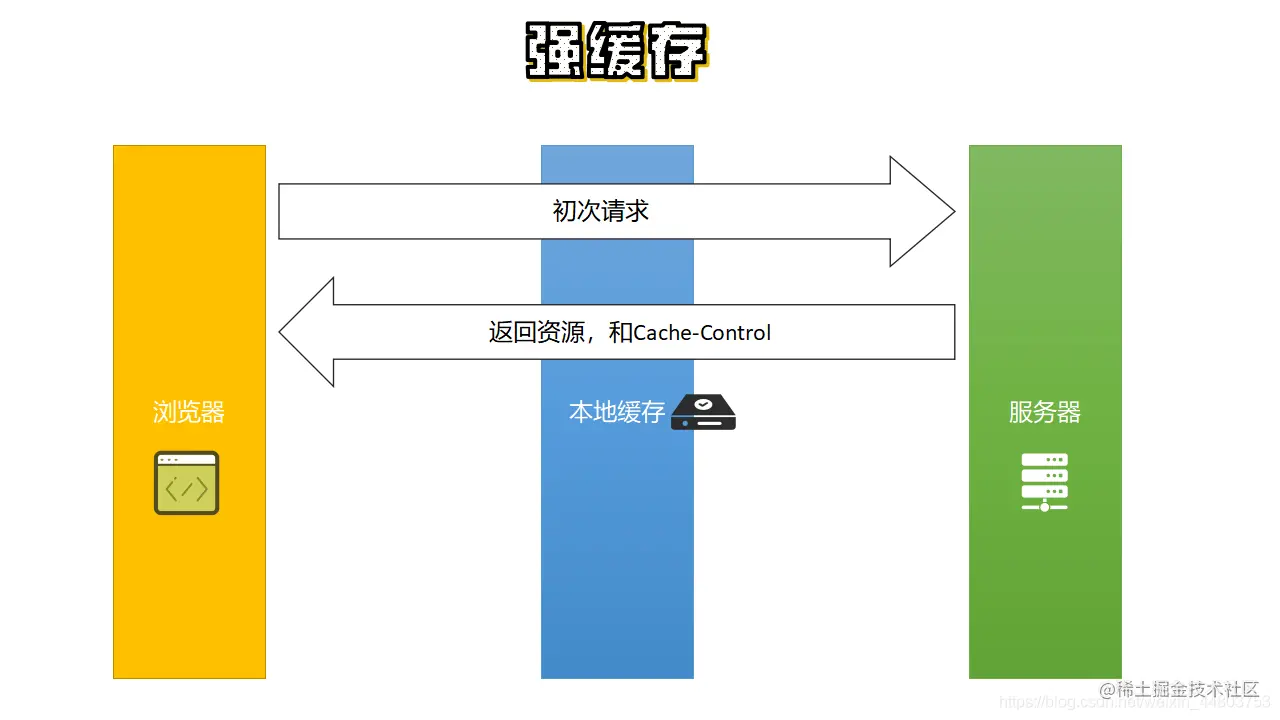
从上图可以看到,当初次请求时,浏览器会向服务器发起请求,服务器接收到浏览器的请求后,返回资源并返回一个 Cache-Control 给客户端,该 Cache-Control 一般设置缓存的最大过期时间。
接下来看第二个图。
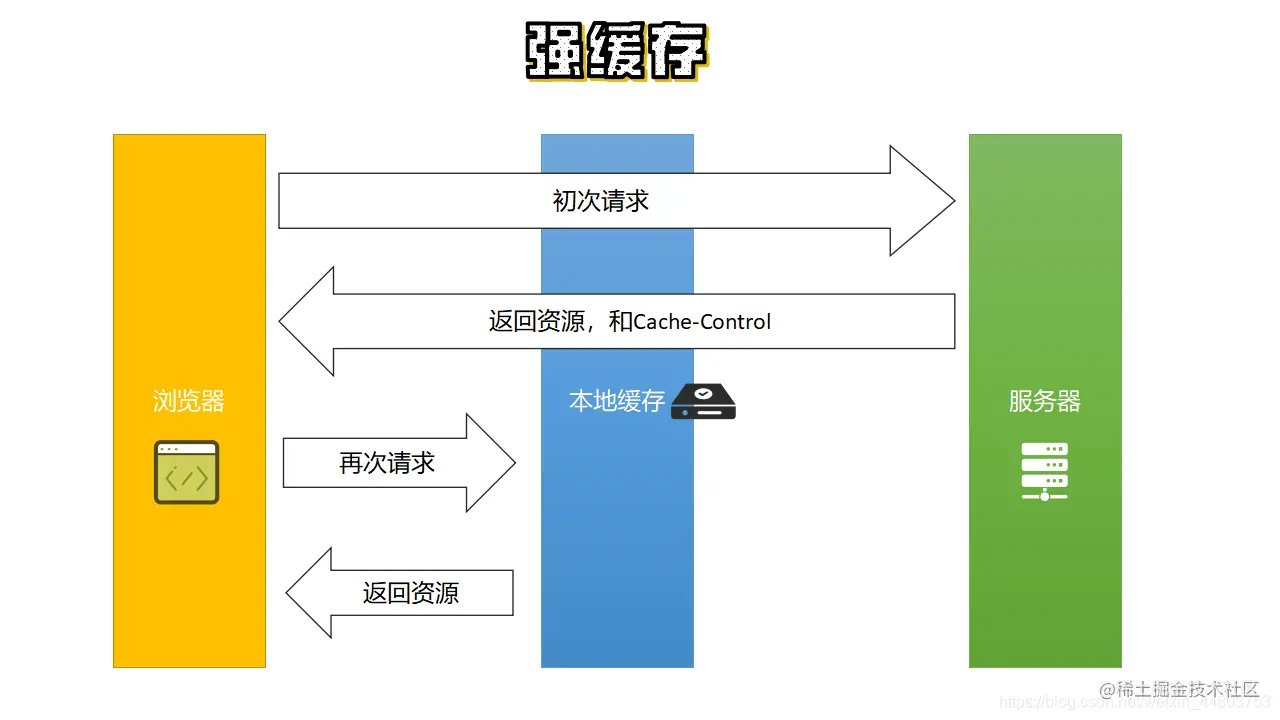
从上图中可以看到,此时浏览器已经接收到 cache-control 的值,那么这个时候浏览器再次发送请求时,它会先检查它的 cache-control 是否过期,如果没有过期则直接从本地缓存中拉取资源,返回到客户端,而无需再经过服务器。
接下来看第三个图。
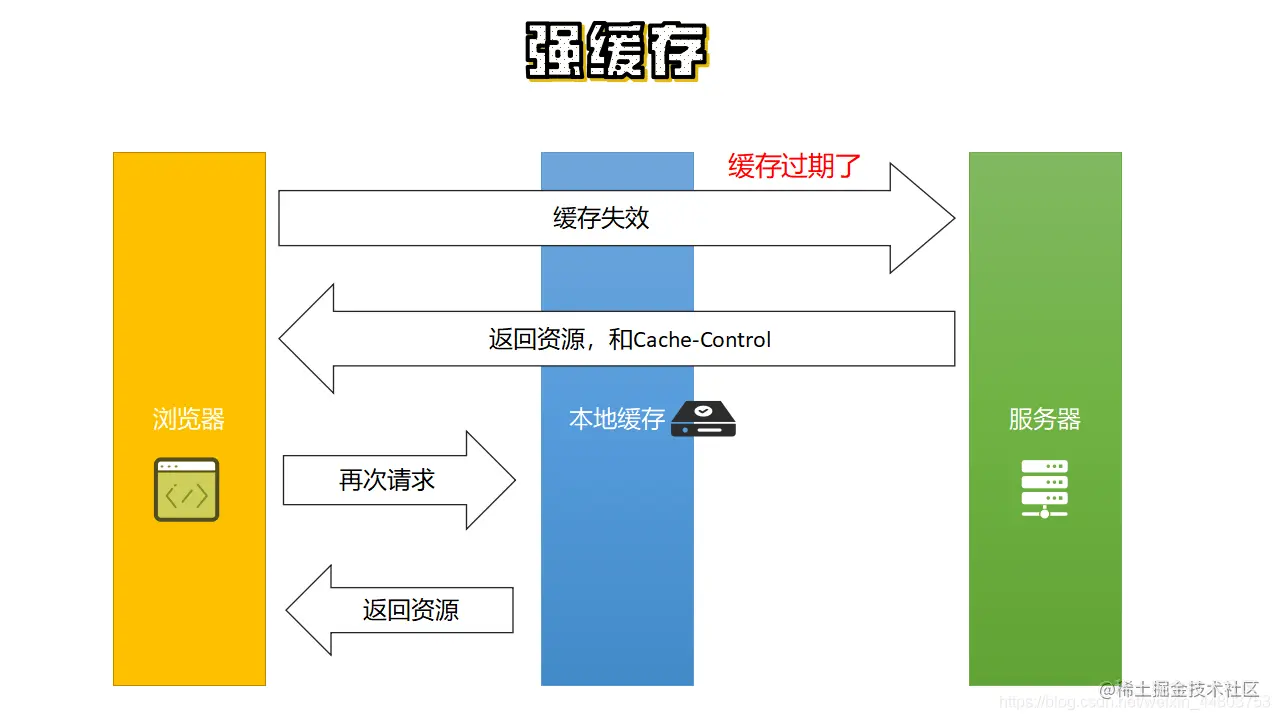
强制缓存有过期时间,那么就意味着总有一天缓存会失效。那么假设某一天,客户端的 cache-control 失效了,那么它就没办法从本地缓存中拉取资源。于是它会像第一张图一样,重新向服务器发起请求,之后服务器会再次返回资源和 cache-control 的值。
以上就是强制缓存的全过程。
3)Cache-Control
Cache-Control是什么?
Cache-Control的值
| Cache-Control值 | 含义 |
|---|
| max-age | 设置缓存的最大过期时间 |
| no-cache | 不用本地缓存,正常的向服务端请求,服务端怎么处理我们不用管 |
| no-store | 简单粗暴,直接从服务端拉取缓存 |
| private | 只能允许最终用户做缓存,最终用户即电脑、手机等等 |
| public | 允许中间路由或中间代理做缓存 |
4)关于Expires
(2)协商缓存
1)协商缓存是什么?
2)图例
同样地,用几张图来演示协商缓存。
先来看第一张图。
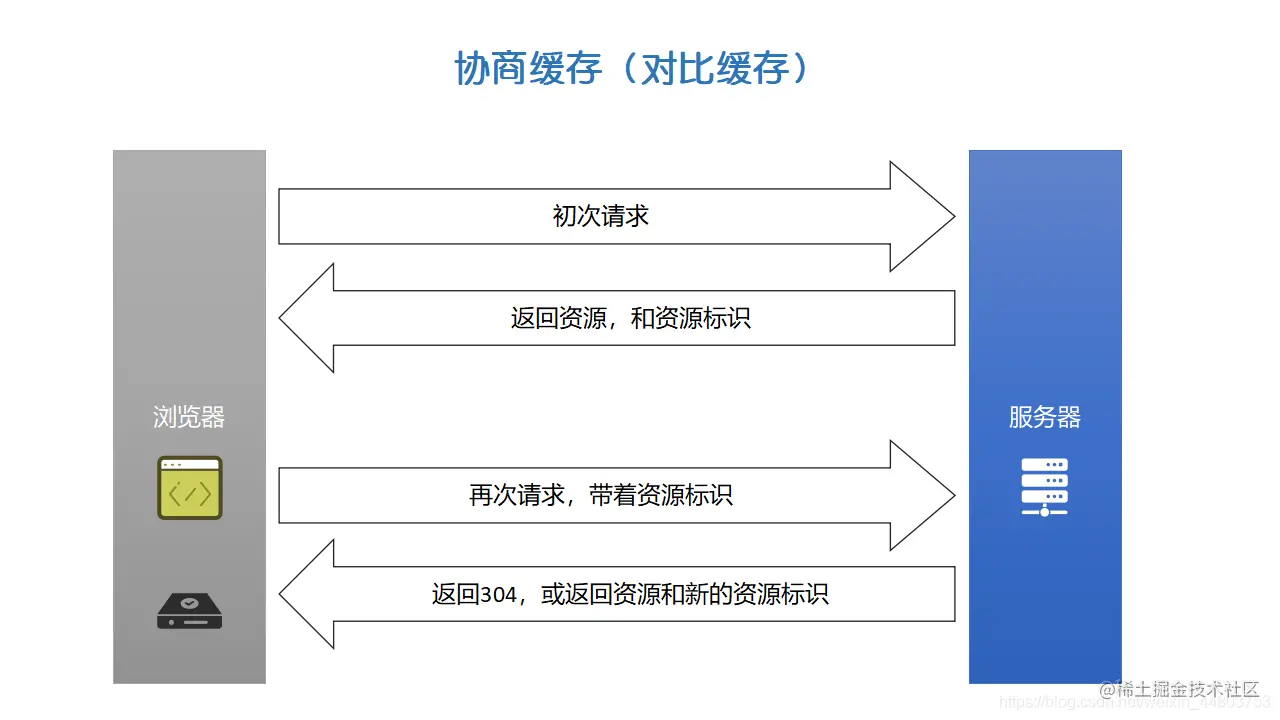
在上图中,表明了协商缓存的全过程。首先,如果客户端是第一次向服务器发出请求,则服务器返回资源和相对应的资源标识给浏览器。该资源标识就是对当前所返回资源的一种唯一标识,可以是Etag或者是Last-Modified,这两个字段将在图例结束后展开讲解。
之后如果浏览器再次发送请求时,浏览器就会带上这个资源标识。此时,服务端就会通过这个资源标识,可以判断出浏览器的资源跟服务端此时的资源是否一致,如果一致,则返回304,即表示Not Found 资源未修改。如果判断结果为不一致,则返回200,并返回资源以及新的资源标识。至此就结束了协商缓存的过程。
接下来看第二张图。
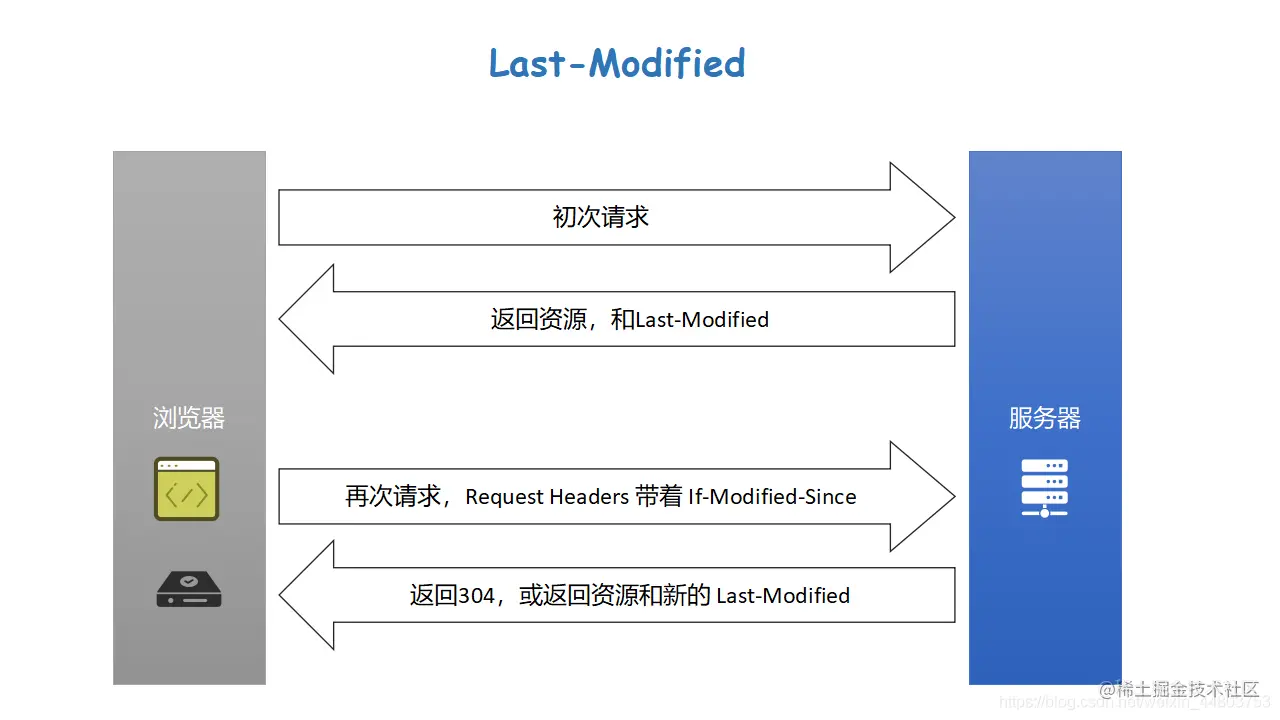
假设此时我们的协商缓存用 Last-Modified 来判断。当浏览器第一次发送请求时,服务器返回资源并返回一个 Last-Modified 的值给浏览器。这个 Last-Modified 的值给到浏览器之后,浏览器会通过 If-Modified-Since 的字段来保存 Last-Modified 的值,且 If-Modified-Since 保存在请求头当中。
之后当浏览器再次发送请求时,请求头会带着 If-Modified-Since 的值去找服务器,服务器此刻就会匹配浏览器发过来的 If-Modified-Since 是否和自己最后一次修改的 Last-Modified 的值相等。如果相等,则返回 304 ,表示资源未被修改;如果不相等,则返回200,并返回资源和新的 Last-Modified 的值。
接下来看第三张图。
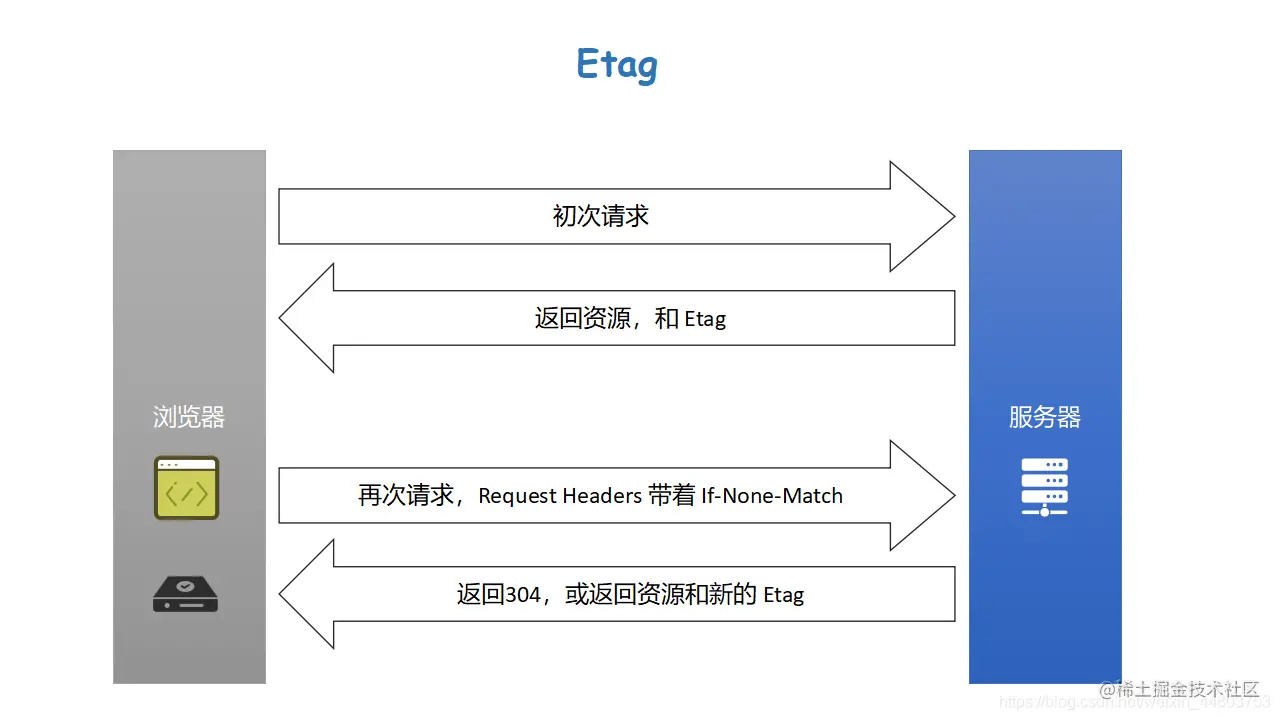
假设此时我们的协商缓存用 Etag 来判断。当浏览器第一次发送请求时,服务器返回资源并返回一个 Etag 的值给浏览器。这个 Etag 的值给到浏览器之后,浏览器会通过 If-None-Match 的字段来保存 Etag 的值,且 If-None-Match 保存在请求头当中。
之后当浏览器再次发送请求时,请求头会带着 If-None-Match 的值去找服务器,服务器此刻就会匹配浏览器发过来的 If-None-Match 是否和自己最后一次修改的 Etag 的值相等。如果相等,则返回 304 ,表示资源未被修改;如果不相等,则返回 200 ,并返回资源和新的 Etag 的值。
通过图例,相信大家对协商缓存有了一个新的认识。接下来讲解刚刚图例中所包含的一些字段。
3)资源标识
在响应头部 Response Headers 中,有两种资源标识:
4)Last-Modified 和 Etag
5)Headers 示例

由上图可以看到,响应头中的 Last-Modified 对应请求头中的 If-Modified-Since , Etag 对应请求头中的 If-None-Match 。
6)流程图
说到这里,协商缓存的内容也快结束啦!最后的最后,我们用一张流程图来展示协商缓存的全过程。
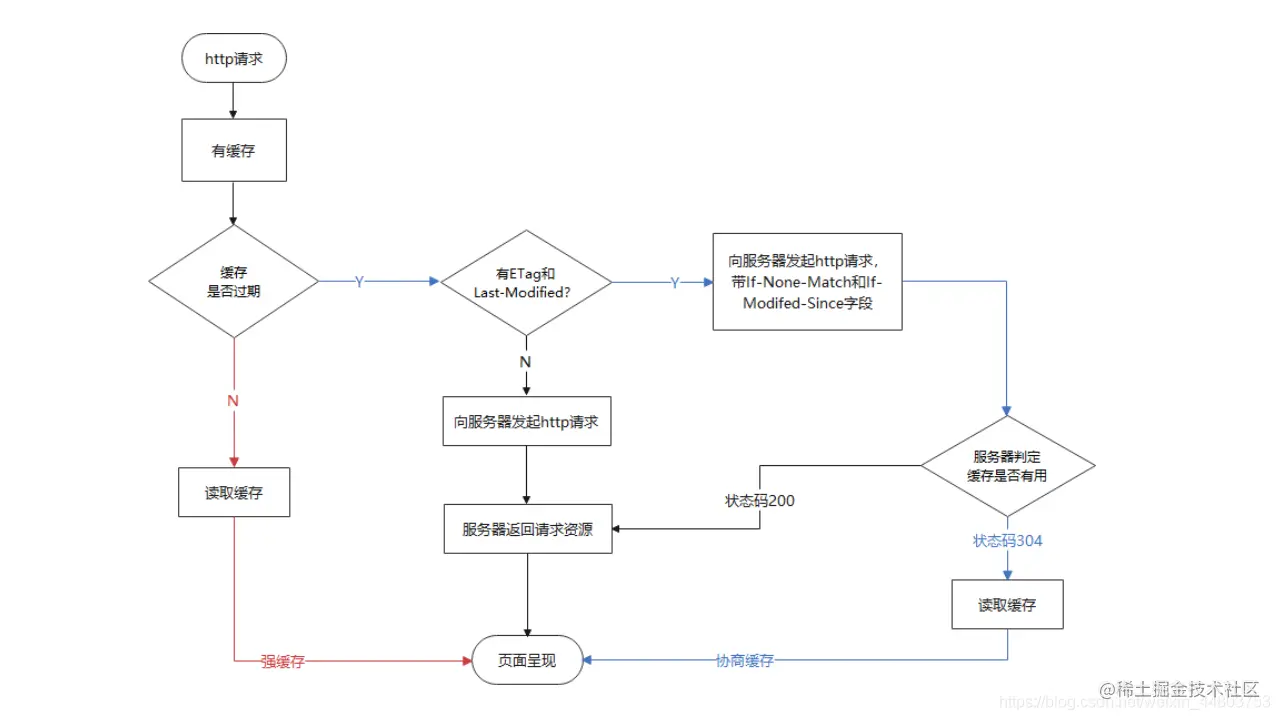
7)协商缓存为什么要有两种呢?
有时候我们的网站是分布式部署在多台服务器上,一个资源文件可能在每台服务器上都有副本,相应地资源文件被修改时,新的文件要同步到各个服务器上,导致各个文件副本的修改时间不一定相同。那么当用户一次访问请求的服务器和另一次访问请求的服务器不同时,就有可能因为两个文件副本的修改时间不同而使得Last-Modified形式的协商缓存失效。
如果这种情况采用Etag形式的协商缓存,根据文件内容而不是修改时间来判断缓存,就不会有这个问题了。
3、刷新操作方式,对缓存的影响
讲完缓存,我们再来讲个有点重要但是有点题外话的内容:刷新操作。我们平常在上网时,总有某个时刻突然网卡了,这个时候人的本性总是非常不耐烦的,毫不犹豫的就来个刷新。但殊不知,刷新对缓存也存在一定的影响。下面我们一起来看下各种刷新姿势以及其对缓存的影响。
(1)正常操作
定义: 地址栏输入 url ,跳转链接,前进后退等。
对缓存的影响: 强制缓存有效,协商缓存有效。
(2)手动刷新
定义: F5 ,点击刷新按钮,右击菜单刷新。
对缓存的影响: 强制缓存失效,协商缓存有效。
(3)强制刷新
定义: ctrl + F5 。
对缓存的影响: 强制缓存失效,协商缓存失效。
这一块内容仅当娱乐补充,大家可以根据自身需求学习~






 400 186 1886
400 186 1886


