大模型长上下文运行的关键问题
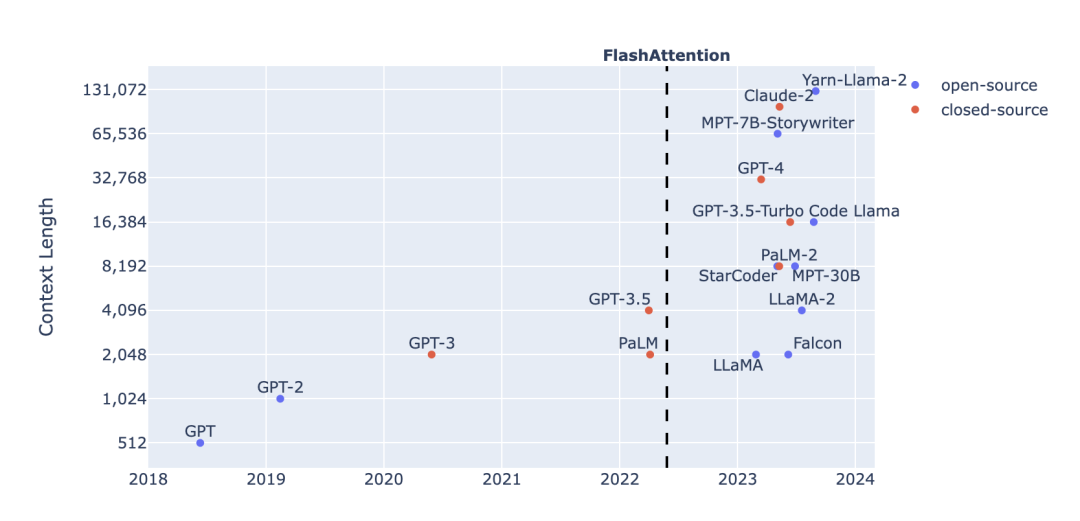
上下文长度的增加是 LLM 的一个显著发展趋势。过去一年,几种长上下文语言模型陆续问世,包括 GPT-4(32k上下文)、MosaicML 的 MPT(65k上下文)、Anthropic 的 Claude(100k上下文)等。然而,扩大 Transformer 的上下文长度是一个挑战,因为其核心的注意力层在时间复杂度和空间复杂度与输入序列长度的平方成正比。
本文作者 Harm de Vries 是 ServiceNow 的研究员,也是其 LLM 实验室的负责人。他认为,长上下文运行的问题在于缺少长预训练数据,而非二次注意力。 本文将深入探讨随上下文长度的增加,注意力层的计算开销情况,并指出常见预训练数据集中序列长度的分布情况。由此,作者针对长上下文运行分析了几个重要问题:是否在固有短序列数据上浪费了注意力计算开销?如何创建有意义的长文本预训练数据?是否可以在训练过程中使用可变的序列长度?以及如何评估长上下文能力? (以下内容在遵循 CC BY-NC-SA 4.0 协议的基础上由 OneFlow 编译发布,译文转载请联系授权。原文:https://www.harmdevries.com/post/context-length/) 作者 | Harm de Vries OneFlow编译 翻译|杨婷、宛子琳 长上下文运行的问题在于缺少长预训练数据,而不是二次注意力。 上下文长度增加是语言大模型的一个显著趋势。上下文长度是指在 Transformer 预测下一个词元之前,我们可以喂入到模型中的词元数量。过去一年,长上下文 LLM(Long-context LLM)的数量显著增加,如下图所示。
FlashAttention 的发明是一个重要的转折点,它以一种巧妙的方式适应了现代 GPU 对注意力计算的需求,提高了计算和内存效率。本文不会详细介绍 FlashAttention 的技术细节,但它消除了 GPU 的内存瓶颈,使 LLM 开发者能够将上下文长度从传统的 2K 词元增加至 8-65K。 有趣的是,如果你仔细观察长上下文 LLM,就会发现其中许多都是由较小上下文窗口的基础 LLM 微调而来的。例如:
为什么会有这两个训练阶段呢?共有两种可能:(1)由于注意力层的二次复杂性,使用长上下文进行训练在计算上太过昂贵;(2)预训练阶段缺乏长序列数据。 本文将深入探讨以上两点:
综合上述观察结果,可以得出结论:虽然使用 16-32K 上下文窗口进行预训练是可行的,但个别文档的词元分布并不适合这种方法。主要问题在于,传统的预训练方法将来自随机文件的词元打包到了上下文窗口中,这导致 16-32K 的词元窗口中包含了许多不相关的文档。假设在预训练期间,LLM 能受益于更具意义的长上下文,本文认为可利用元数据创建更长的预训练数据,例如通过超链接连接网页文档,以及通过代码库结构连接代码文件。 1上下文长度对 Transformer 浮点运算(FLOP)的影响让我们从注意力层的计算开销开始。我们将估算训练 Transformer 模型所需的计算量。具体来说,我们将计算模型在前向传播和反向传播过程中的矩阵乘法所需的浮点运算(FLOPs)。为更好地进行研究,我们将 FLOPs 分为三组:前馈层(FFN)中的稠密层,查询、键、值、输出的投影(QKVO),以及计算查询-键(query-key)得分和值嵌入(value embeddings)的加权求和(Att)。 对于具有
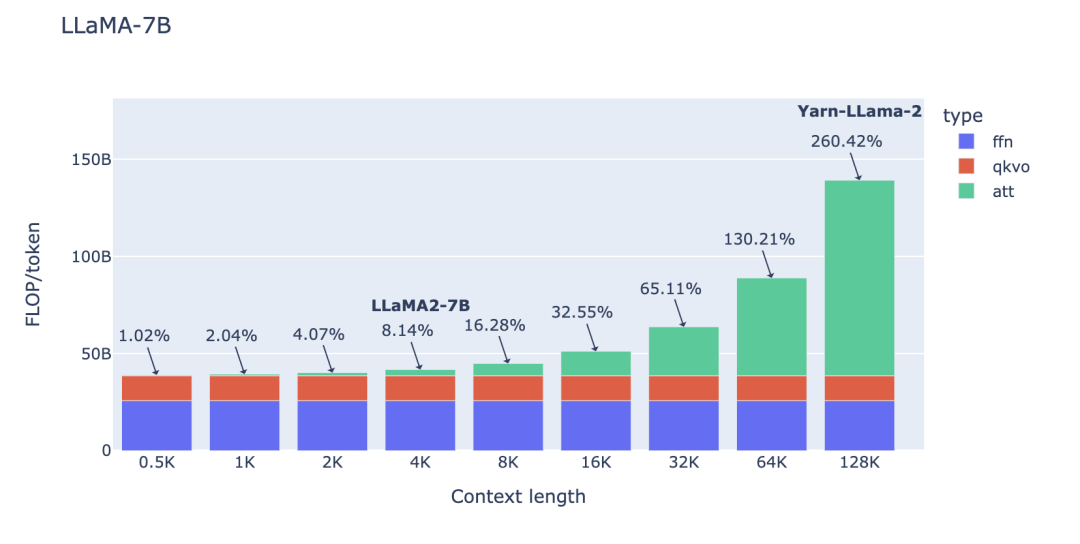
可参阅附录以获取详细推导过程https://www.harmdevries.com/post/contextlength/#appendix)。值得强调的是,我们研究 FLOPs/token 以便在不同上下文长度之间进行有意义的比较。同时请注意, 现在让我们研究一下上述三项在增加上下文长度时对总 FLOPs/token 的贡献。下面,我们展示了 LLaMA-7B 模型的细分情况,其中
如图所示,对于 4K 的上下文窗口,注意力 FLOPs 的贡献相对较小(8%)。这是 LLaMA-2 和其他几个基础 LLM 模型的预训练阶段,其中注意力 FLOPs 对计算的影响可以忽略不计。然而,当使用 128K 的超大上下文窗口(如 Yarn-Llama-2)时,注意力 FLOPs 就成了主导因素,造成了 260% 的计算开销。 这意味着,如果使用 2K 上下文窗口进行完整的预训练需要 1 周时间,那么使用 128K 的上下文长度则预计需要 3.5 周的时间。当然,这是在训练过程中使用的词元数相同(例如通过减小批量大小)的情况下。考虑到计算时间的大幅增加,许多研究和开发人员只愿意在微调阶段承担这样的开销。在这两个极端之间存在这一个有吸引力的折中方案,例如,使用 8-16K 的上下文窗口只会增加 16-33% 的计算开销,这是可以接受的。这就是我们为 StarCoder 选择的折中方案,它使用 8K 的上下文长度,用超过 1 万亿个词元进行了预训练。 许多人往往低估了模型大小对注意力计算开销的影响程度。无论是 FFN FLOPs、QKVO FLOPs(以及模型参数)都与隐藏状态维度
对于 GPT3-170B( 总的来说,我认为在当前的模型规模下,使用 16-32K 范围内的基础模型进行训练是非常合理的。正如我将在接下来的部分中解释的,目前的主要瓶颈是数据集不适合使用如此长的上下文进行预训练。 2预训练数据的序列长度接下来,我们将研究常见的预训练数据集中的序列长度分布,首先来观察下表中 LLaMA 模型的训练数据。
可以看到,CommonCrawl 是 LLaMA 训练数据集的主要数据来源,CommonCrawl 是一个公开可用的互联网抓取数据集。实际上,C4 的数据也是从 CommonCrawl 中获取的,因此这个数据源占据了 LLaMA 训练数据的 80% 以上。其他数据来源(如Github、ArXiv、Wikipedia和书籍)只贡献了一小部分训练数据。值得注意的是,MPT-30B 和 OpenLLaMA-7B 基本遵循了相同的数据分布,而 Falcon-40B 甚至仅使用了 CommonCrawl 数据进行训练(参见 RefinedWeb 数据集)。 相反,用于代码的 LLM 通常是在 Github 的源代码上进行训练的。StarCoder、Replit-3B、CodeGen2.5 和 StableCode 都使用了 The Stack,这是一个包含了 Github 上许可放宽的代码库构成的预训练数据集。 我们将分析这些预训练数据集的序列长度分布,其中主要分析 CommonCrawl 和 Github,此外,我们还会分析一些较小的数据集(如 Wikipedia 和 Gutenberg 图书),以供参考。对于每个数据源,我们将随机选择 10000 个样本,对样本进行词元化,并保存序列长度。随后,我们会创建柱状图以可视化序列长度的分布情况,并查看每个区间(即文档计数)有多少文档或文件。此外,我们还将评估每个区间内的词元数量,因为我们注意到一些较长的文件可能会对统计数据产生较大的影响。需要注意的是,对于纯文本数据源(CommonCrawl、Wikipedia、Gutenberg),我们使用的是 Falcon 分词器,而处理源代码(The Stack)时,我们使用的是 StarCoder 分词器。 2.1 CommonCrawl 首先,我们分析的是 CommonCrawl 数据集,并查看了 RefinedWeb 和 C4 数据集。从图中可以看出,C4 和 RefinedWeb 中有相当大一部分的文件都相对较短,其中超 95% 的文件包含的词元不足 2K。因此,将上下文窗口扩展到 2K 以上,只能为其中 5% 的文件捕获更长的上下文!
然而,你可能会认为,我们关心的是每个区间内的词元数量而不是文件数量。确实,当我们观察下图中的词元数量时,情况略有不同。在 RefinedWeb 中,将近 45% 的词元来自超 2K 个词元的文件。因此,将上下文长度增加到 2K 以上,对于 45% 的词元来说可能仍然是有益的。至于剩余的 55%,我们会将来自随机文件的词元连接到上下文窗口中。我认为,这对模型的帮助不大,甚至可能影响模型性能。 如果我们将上下文窗口扩展到 8K,那么几乎有 80% 的词元可以完全适应上下文窗口,换言之,只有 20% 的词元可能会从超 8K 的更长上下文中受益。
该图表中还可以看出另一个明显差异——即 RefinedWeb 数据集比 C4 数据集具有更多的长文件。可以看到,RefinedWeb 中超过 16K 个词元的文件占比超 12.5%,而 C4 则不到 2.5%。有趣的是,尽管这两个数据集都来自同一来源,但其序列长度分布的差异却如此之大。 2.2 Github 接下来,我们来看看 starcoderdata 中的不同编程语言、Github issues 和 Jupyter Notebook, starcoderdata 是用于训练 StarCoder 的 The Stack 子集。对于所有编程语言,我们可以观察到大多数文件都很短:80% 以上的文件词元量不超过 3K,Github issues 往往也比较短,只有 Jupyter Notebook 的上下文稍长,尽管超过 80% 的文件仍然少于 5K 词元。
从文档柱状图中,我们还可以看到 Github 中的长文件比 CommonCrawl 多。当我们观察下面的词元柱状图时,这种长尾效应更加明显。具体而言,在 C 编程语言的情况下,超 50% 的词元来自于超 16K 个词元的文件——尽管这些文件的比例不到 5%!在对这些长文件进行人工检查时,我发现有些文件的词元超过了 300K。许多这样的长文件似乎是大型的宏和函数集合。当然,你可能会质疑这些文件中有多少是有意义的长上下文结构。
从更广泛的视角来看,考虑到其他编程语言,可以明显看到较长的代码文件比 Web 文档更多。如果排除 C 语言和 Javascript,我们会发现大约 50-70% 的词元来自少于 8,000 个词元的文件,而对于 RefinedWeb 数据集,这一比例接近 80%。 2.3 其他资源 正如预期的那样,我们可以在其他预训练数据来源(如 Wikipedia 和图书)中可以找到更多的长文档。在下面的柱状图中,我们观察到,超 50% 的 Wikipedia 文章的词元数超过了 4000。就图书而言(比如 LLaMA 数据集中包含的 Gutenberg 图书集),我们甚至发现超 75% 的图书含有超 16000个词元。
尽管以上图表证实这些数据源比 CommonCrawl 和 Github 具有更多的长上下文结构,但它们在训练数据中所占的比例通常较小。原因如下:首先这些数据源能够提供的数据量有限,不适合大规模预训练,例如 Wikipedia 只包含约 80GB 数据,而 CommonCrawl 则可以提供几 TB 的数据;其次,这些数据(例如图书)的网络覆盖率不足,所以模型训练数据中的图书比例也很少(LLaMA 为4.5%,MBT-30B 为3%)。 3 讨论 3.1 是否在固有短序列数据上浪费了注意力计算开销? 经前文分析,可以看出 CommonCrawl 和 Github 是训练 SOTA 开源语言模型的主要数据来源,其中相当一部分(约 80-90%)示例的长度都不超过 2K 个词元。这一结果表明,仅将上下文窗口扩展到 8-32K 可能不会带来显著的性能提升。在预训练期间,我们通常将多个输入示例组合成一个序列,直至达到最大的上下文长度。如果两个拼接训练示例之间没有关联,我们就在那些不需要彼此通信的词元上浪费了注意力机制的计算开销。 换句话说,尽管我们看到使用 16-32K 上下文窗口进行训练的计算开销对于当前模型大小来说是可行的,但在预训练期间,我们尚未找到可有效利用这个更大的上下文窗口的方法。 3.2 如何创建有意义的长文本预训练数据? 虽然其他来源(如书籍和科学文章)能够提供比 CommonCrawl 和 Github 更长的上下文,但这些数据是否包含足够的广度和多样性来训练高性能的 LLM 仍然存疑。在这种情况下,一种选择是,寻找更多样化的长上下文数据来源,例如通过出版社获得其他教科书或教程的许可。此外,我认为利用数据源的元数据(结构)可能是另一个可行途径:
3.3 是否可以在训练过程中使用可变的序列长度? 不同于将训练分为两个阶段(即短序列的预训练阶段和长序列的微调阶段),我们也可以使用多个序列长度进行训练。具体而言,我们可以将预训练数据划分为不同的 bucket(如小于2K,小于 16K 等),并根据每批(或每 X 批)数据调整上下文长度。这样,我们只需在具有长上下文的文件上承担注意力计算开销。当然,目前尚不清楚这种方法是否比两阶段训练过程更加有效。 3.4 如何评估长上下文能力? 缺乏合适的基准测试也许是评估长上下文能力的一个主要障碍。虽然可以通过一些用例来进行测试,如仓库级代码补全或对长篇财务报告或法律合同进行问答和摘要,但我们尚未建立针对这些应用程序的良好基准测试。此外,正如 CodeLLaMA 论文所指出的,研究人员采用了一些代理任务(proxy task)来测量长代码文件的困惑度(perplexity)或合成的上下文检索任务(synthetic in-context retrieval task)的性能。 虽然在缺乏适当评估基准的情况下,我们无法准确评估新的长上下文语言模型的有效性。但我相信,随着时间的推移,研究界和开源社区将解决此评估问题。目前,我所提出的扩展上下文长度的建议是否有效尚不确定,但我希望通过以上分析,能帮助读者更好地理解上下文长度、计算开销和(预)训练数据之间的权衡。 4局限性
附录:推导 Transformer 的 FLOPs Transformer 在我们开始计算 FLOPs 之前,需要定义 Transformer 模型中的运算。此处我们只关注Transformer 层,排除了词元嵌入、位置编码和输出层,对于大型模型来说,这些部分的影响很小。因此,我们从嵌入
MatMul FLOPs 了解模型执行前向和后向传播所需的浮点运算数量(FLOPs)是非常重要的背景信息。下文详细介绍了最耗费 FLOPs 的操作:矩阵乘法。 参照矩阵乘法的数学公式
Transformer 的 FLOPs 数量 下面是 Transformer 层中不同部分所需的 FLOPs 数量。只考虑矩阵乘法,不包括层归一化、GeLU 激活和残差连接等逐元素操作,也不考虑执行优化 step 所需的 FLOPs 数。 FFN FLOPs
QKVO FLOPs
注意力 FLOPs
单个词元的 FLOPs
正如下面将要讨论的,因为我们没有考虑语言模型的自回归特性,所以这实际上高估了注意力 FLOPs。 注意力 FLOPs 被高估了 请注意,对于自回归解码器模型而言,词元只会关注先前的词元序列。这意味着注意力分数矩阵S是一个下三角矩阵,不需要计算上三角部分。因此,方程10中的计算仅需要
与 6ND FLOP 的近似关系 我们很容易就能得到 6ND 这个近似 Transformer 训练 FLOPs 的公式 。首先,
用于训练的词元数 D 由 转自:https://blog.csdn.net/OneFlow_Official/article/details/133110112 该文章在 2024/1/27 15:54:24 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886




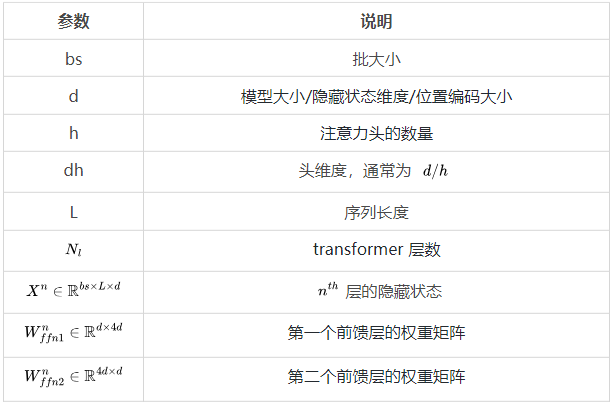
 个Transformer 层、一个隐藏状态维度
个Transformer 层、一个隐藏状态维度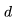 和上下文长度
和上下文长度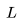 的模型来说,每个词元的 FLOPs(FLOPs/token)细分如下:
的模型来说,每个词元的 FLOPs(FLOPs/token)细分如下: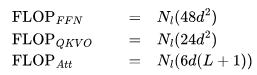
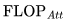 是唯一与上下文长度
是唯一与上下文长度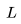 有关的项。
有关的项。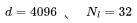 。在每个柱状图顶部,展示了注意力 FLOPs 的相对贡献:
。在每个柱状图顶部,展示了注意力 FLOPs 的相对贡献: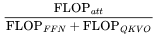 。
。
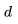 的平方成正比。对于 LLaMA-65B(
的平方成正比。对于 LLaMA-65B(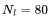 ),维度
),维度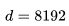 是 LLaMA-7B 大小的两倍;这意味着,我们可以将上下文长度增加一倍,而计算开销保持不变!换句话说,与使用 16-32K 的上下文窗口产生的开销相同,都在 16-33% 范围内。
是 LLaMA-7B 大小的两倍;这意味着,我们可以将上下文长度增加一倍,而计算开销保持不变!换句话说,与使用 16-32K 的上下文窗口产生的开销相同,都在 16-33% 范围内。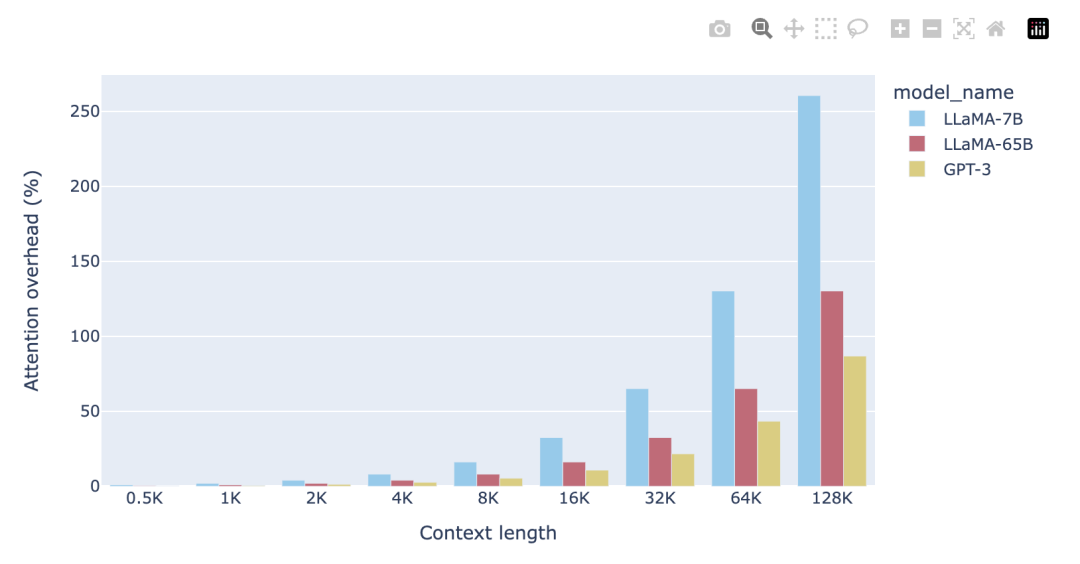
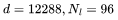 )等更大的模型,可以将上下文窗口增加到 64K,并产生几乎相同的计算开销(40%)。尽管我们不确定是否需要如此大的模型,详情请参见之前的文章。
)等更大的模型,可以将上下文窗口增加到 64K,并产生几乎相同的计算开销(40%)。尽管我们不确定是否需要如此大的模型,详情请参见之前的文章。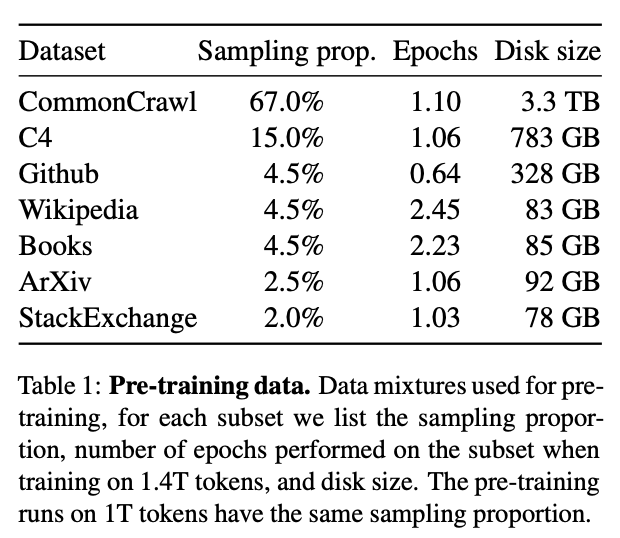





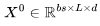 开始,然后通过 J 个 Transformer 层进行传递——参见下图中的定义。需要注意的是,许多运算都是批量矩阵乘法,其中权重矩阵在第一个维度(bs)被广播。
开始,然后通过 J 个 Transformer 层进行传递——参见下图中的定义。需要注意的是,许多运算都是批量矩阵乘法,其中权重矩阵在第一个维度(bs)被广播。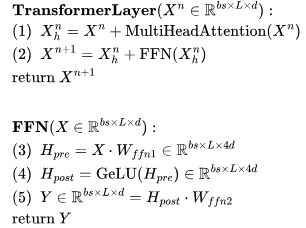

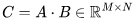 ,其中有输入矩阵
,其中有输入矩阵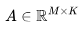 和
和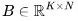 。得到的矩阵
。得到的矩阵 包含
包含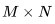 个元素, 每个元素通过对 K 个元素(element)进行点积而得到。因此,我们需要
个元素, 每个元素通过对 K 个元素(element)进行点积而得到。因此,我们需要 个运算来计算矩阵乘法,其中每个运算都涉及乘法和加法,因此总的 FLOPs 数量是
个运算来计算矩阵乘法,其中每个运算都涉及乘法和加法,因此总的 FLOPs 数量是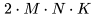 ,详情可参考 Nvidia 的文档(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。
,详情可参考 Nvidia 的文档(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。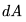 和
和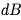 。根据 CS231n 的讲座笔记,它们的计算公式如下:
。根据 CS231n 的讲座笔记,它们的计算公式如下: . 因为
. 因为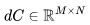 和
和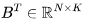 ,有
,有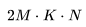 FLOPs。
FLOPs。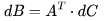 . 因为
. 因为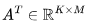 和
和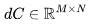 ,有
,有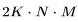 FLOPs。
FLOPs。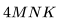 ,
,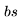 乘以
乘以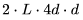 。
。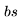 乘以
乘以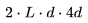 。
。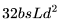 。
。 个 FLOPs。
个 FLOPs。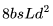 ,后向传播的 FLOPs 数为
,后向传播的 FLOPs 数为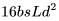
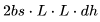 FLOPs。
FLOPs。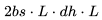 FLOPs。
FLOPs。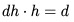 , 所以总的 FLOPs 简化为
, 所以总的 FLOPs 简化为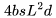 ,用于前向传播,而后向传播需要的 FLOPs 为
,用于前向传播,而后向传播需要的 FLOPs 为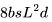 。
。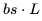 。此外,我们已经计算了单个 Transformer 层的 FLOPs,并且需要乘以
。此外,我们已经计算了单个 Transformer 层的 FLOPs,并且需要乘以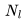 来得到总的 FLOPs。这得出以下三项:
来得到总的 FLOPs。这得出以下三项: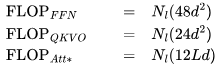
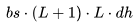 个 FLOPs。类似地,在注意力输出计算中(方程12),矩阵P是一个下三角矩阵,因此 FLOPs 减少至
个 FLOPs。类似地,在注意力输出计算中(方程12),矩阵P是一个下三角矩阵,因此 FLOPs 减少至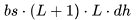 。每个词元总的注意力 FLOPs 为:
。每个词元总的注意力 FLOPs 为: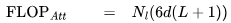
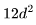 给出了Transformer 层的参数数量。因此,总的参数数量N与 FLOPs/token 之间的关系如下:
给出了Transformer 层的参数数量。因此,总的参数数量N与 FLOPs/token 之间的关系如下: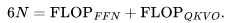
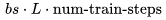 得到。值得注意的是,这个近似忽略了
得到。值得注意的是,这个近似忽略了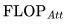 。正如我们所见,对于 2K 上下文窗口,该项很小,但对于更长的上下文窗口,它开始占主导地位。
。正如我们所见,对于 2K 上下文窗口,该项很小,但对于更长的上下文窗口,它开始占主导地位。