为什么JOIN查询比子查询快?—— 驱动表选择的秘密
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
摘要: 通过EXPLAIN分析、Nested Loop算法图解、以及驱动表选择的性能对比,揭秘为什么MySQL对子查询的优化很弱、JOIN如何选择最优驱动表、以及什么时候必须用子查询。配合时序图展示查询流程,给出JOIN优化的5个最佳实践。 一天下午,运营同学反馈数据导出功能超时。
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 类型 | 含义 | 性能 | ||||||
| SIMPLE | 简单查询(无子查询) | ⭐⭐⭐⭐⭐ | ||||||
| PRIMARY | 主查询 | - | ||||||
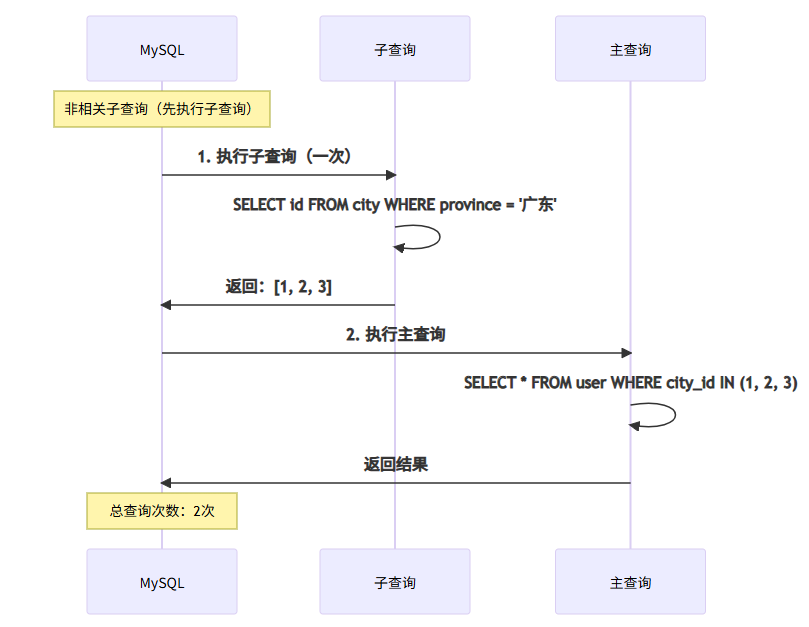
| SUBQUERY | 非相关子查询 | ⭐⭐⭐ | ||||||
| DEPENDENT SUBQUERY | 相关子查询 | ⭐ 慢 | ||||||
| DERIVED | 派生表(FROM子查询) | ⭐⭐ |
示例:
SELECT u.*, o.*
FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- 假设:
-- user表:1000行
-- order_info表:100万行
-- order_info.user_id有索引
执行流程:
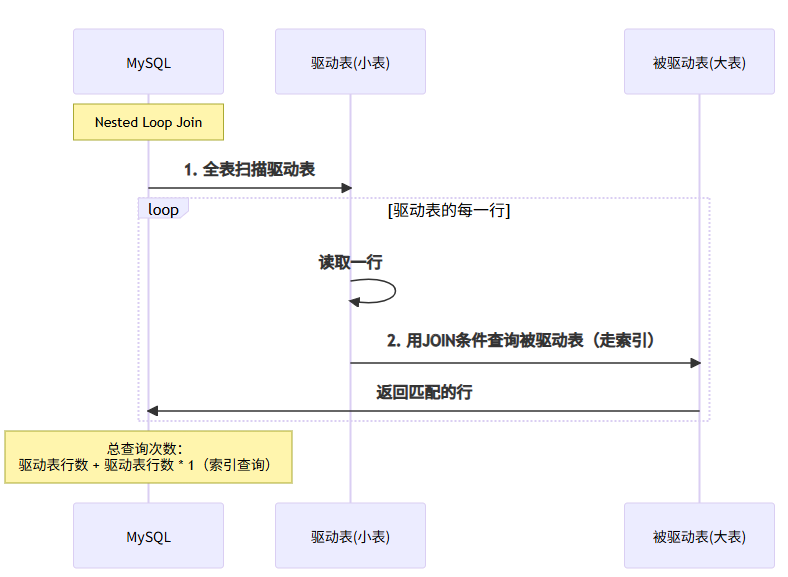
1. 扫描user表(1000行)← 驱动表
2. 每个user.user_id在order_info中查询(走索引,很快)
3. 总查询次数:1000 + 1000 = 2000次(索引查询很快)
✅ 小表做驱动表
✅ 被驱动表的JOIN列必须有索引
原则:选择结果集小的表做驱动表
规则:
1. INNER JOIN:优化器自动选择小表
2. LEFT JOIN:左表是驱动表(固定)
3. RIGHT JOIN:右表是驱动表(固定)
-- INNER JOIN(优化器自动选择)
EXPLAIN SELECT * FROM user u INNER JOIN order_info o ON u.user_id = o.user_id\G
*************************** 1. row ***************************
id: 1
table: u ← user表做驱动表(user表小)
type: ALL
rows: 1000
*************************** 2. row ***************************
id: 1
table: o ← order_info做被驱动表
type: ref
key: idx_user_id
rows: 50 ← 每个user_id匹配50个订单
驱动表:user(1000行)
被驱动表:order_info(100万行)
总扫描次数:
1000(驱动表) + 1000 * 1(索引查询) = 2000次
如果反过来(order_info做驱动表):
100万(驱动表) + 100万 * 1(索引查询) = 200万次
性能差距:1000倍!
-- LEFT JOIN:左表固定是驱动表
SELECT * FROM order_info o
LEFT JOIN user u ON o.user_id = u.user_id;
-- 驱动表:order_info(100万行)← 大表做驱动表(危险)
-- 被驱动表:user(1000行)
EXPLAIN:
table: o
type: ALL
rows: 1000000 ← 扫描100万行
table: u
type: eq_ref
key: PRIMARY
rows: 1
-- ❌ 错误(大表做驱动表)
SELECT * FROM order_info o LEFT JOIN user u ON o.user_id = u.user_id;
-- ✅ 正确(小表做驱动表)
SELECT * FROM user u LEFT JOIN order_info o ON u.user_id = o.user_id;
-- 或者改成RIGHT JOIN
SELECT * FROM user u RIGHT JOIN order_info o ON u.user_id = o.user_id;
user表:100万行
order_info表:500万行
order_info.user_id有索引
-- 子查询(相关子查询)
SELECT * FROM user
WHERE user_id IN (
SELECT user_id FROM order_info
);
-- 执行时间:32.5秒
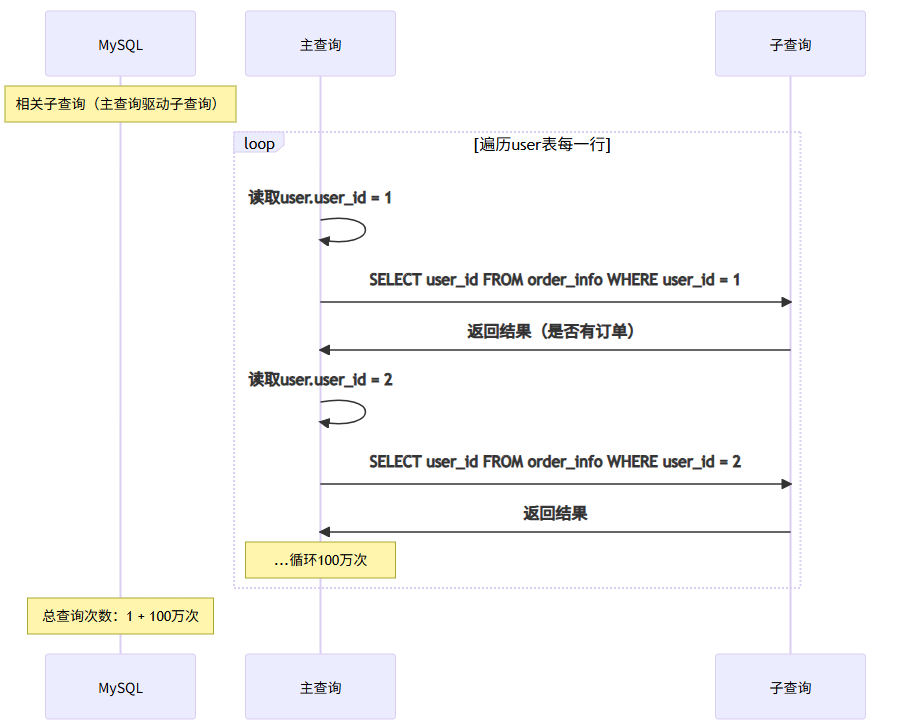
-- 扫描次数:1 + 100万次
-- JOIN
SELECT DISTINCT u.*
FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- 执行时间:0.8秒
-- 扫描次数:1 + 100万次(但走索引,很快)
-- 性能提升:40倍
-- 小表驱动大表(正确)
SELECT * FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- 执行时间:0.8秒
-- 驱动表:user(100万行)
-- 大表驱动小表(错误,用STRAIGHT_JOIN强制)
SELECT * FROM user u
STRAIGHT_JOIN order_info o ON u.user_id = o.user_id;
-- 执行时间:12.3秒
-- 驱动表:order_info(500万行)
-- 性能差距:15倍
测试3:被驱动表无索引:
-- 被驱动表有索引
SELECT * FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- 执行时间:0.8秒
-- 删除索引
ALTER TABLE order_info DROP INDEX idx_user_id;
-- 被驱动表无索引
SELECT * FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- 执行时间:85秒(超时)
-- 性能差距:100倍以上
同事C:“看到了吗?被驱动表的索引至关重要!”
场景1:聚合函数后再过滤
-- 查询订单数超过10的用户
SELECT u.* FROM user u
WHERE (
SELECT COUNT(*) FROM order_info o WHERE o.user_id = u.user_id
) > 10;
-- 改写成JOIN很复杂:
SELECT u.* FROM user u
INNER JOIN (
SELECT user_id, COUNT(*) AS order_count
FROM order_info
GROUP BY user_id
HAVING order_count > 10
) o ON u.user_id = o.user_id;
推荐:这种场景用子查询更简洁。
场景2:NOT EXISTS
-- 查询没有下过订单的用户
SELECT * FROM user u
WHERE NOT EXISTS (
SELECT 1 FROM order_info o WHERE o.user_id = u.user_id
);
-- 改写成LEFT JOIN:
SELECT u.* FROM user u
LEFT JOIN order_info o ON u.user_id = o.user_id
WHERE o.user_id IS NULL;
推荐:NOT EXISTS语义更清晰。
-- 删除没有订单的用户
DELETE FROM user
WHERE user_id NOT IN (
SELECT DISTINCT user_id FROM order_info
);
-- 必须用子查询(无法改成JOIN)
实践1:小表驱动大表
-- ✅ 正确
SELECT * FROM small_table s
INNER JOIN large_table l ON s.id = l.s_id;
-- ❌ 错误(如果用LEFT JOIN)
SELECT * FROM large_table l
LEFT JOIN small_table s ON l.s_id = s.id;
-- 改成RIGHT JOIN
SELECT * FROM small_table s
RIGHT JOIN large_table l ON s.id = l.s_id;
实践2:被驱动表的JOIN列必须有索引
-- 检查索引
SHOW INDEX FROM order_info;
-- 如果没有,创建索引
CREATE INDEX idx_user_id ON order_info(user_id);
实践3:避免SELECT
-- ❌ 错误
SELECT * FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
-- ✅ 正确(只查需要的列)
SELECT u.username, u.phone, o.order_no, o.amount
FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id;
实践4:用STRAIGHT_JOIN强制驱动表
-- 如果优化器选错了驱动表,用STRAIGHT_JOIN强制
SELECT * FROM small_table s
STRAIGHT_JOIN large_table l ON s.id = l.s_id;
-- STRAIGHT_JOIN:强制按写的顺序(small_table做驱动表)
实践5:子查询改写成JOIN
-- ❌ 子查询(慢)
SELECT * FROM user
WHERE user_id IN (
SELECT user_id FROM order_info WHERE status = 1
);
-- ✅ JOIN(快)
SELECT DISTINCT u.*
FROM user u
INNER JOIN order_info o ON u.user_id = o.user_id
WHERE o.status = 1;
主要原因:
1.MySQL对子查询优化很弱
容易产生相关子查询(DEPENDENT SUBQUERY)
相关子查询会执行N次(N=外表行数)
2.JOIN可以选择最优驱动表
自动选择小表做驱动表
大大减少查询次数
3.JOIN可以利用索引
被驱动表走索引查询(eq_ref/ref)
子查询可能无法利用索引
性能对比:
子查询:1 + 100万次查询
JOIN:1000次扫描 + 1000次索引查询
什么时候用子查询:
NOT EXISTS(语义清晰)
聚合后再过滤
UPDATE/DELETE中的子查询
逻辑更清晰的场景
优化建议:
小表驱动大表
被驱动表JOIN列建索引
能改JOIN就改JOIN
用EXPLAIN检查执行计划
参考文章:原文链接






 400 186 1886
400 186 1886